Generate LLM Training Data
Transfer your knowledge into Subsymbolic Information
Training data is crucial for own language models (LLMs) because it enables the models to learn from actual user interactions.
By analyzing these conversations, the models can identify patterns, understand context, and improve their ability to generate accurate and relevant responses. For chemists, this means that the LLM can better understand and respond to queries.
In the Paramus system, creating training data for LLMs involves a structured process that leverages historical chat interactions. This process begins by collecting chat histories, which are sequences of conversations between users and the system. These chat logs are essential as they provide real-world examples of how users interact with the system, including the types of questions asked and the responses given.
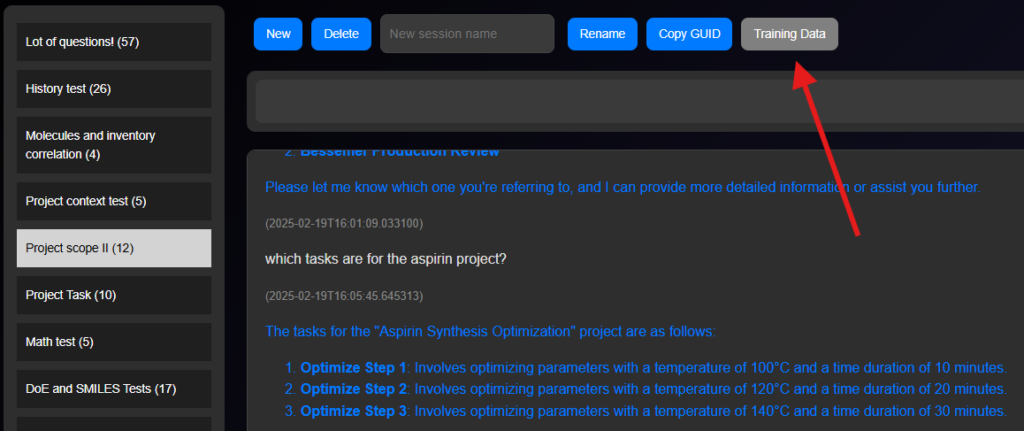
The process of creating training data in Paramus involves using a language model to generate concise prompt-completion pairs from the chat history.
These pairs are formatted in JSON and include a prompt (the user’s query) and a completion (the system’s response). By limiting the pairs to a representative sample of the chat entries (50%), the system ensures that the training data is both manageable and comprehensive.
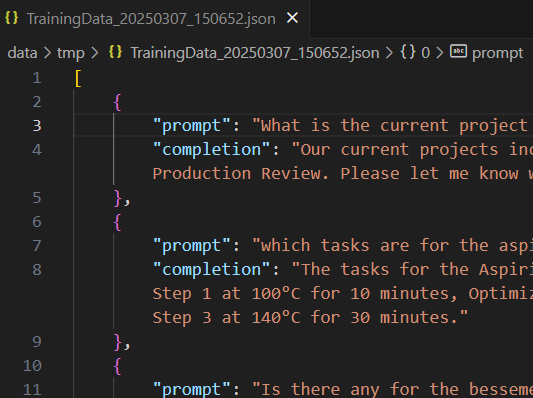
Example for upload and fine-tune in openAI
Once your file is ready, you upload it using OpenAI’s command-line interface (CLI) with openai files create -p fine-tune -f your_file.jsonl. After uploading, you start the fine-tuning process by running openai fine_tunes.create -t file-id -m base-model, where file-id is the uploaded file’s identifier and base-model is the model you want to fine-tune (e.g., gpt-4.5). OpenAI processes the job, and when completed, it provides a new model ID, which you can use like any other OpenAI model.
Paramus CHEMIST allows a continuous feed of your training data.